
HTTP POST LRU caching in JavaScript
I recently published in GitHub the second version of a library of mine, for administrative tables. The first version of this library helped many, who contacted me in the last months, asking things and giving great advice; so I decided to create a new, improved version, in plain vanilla JavaScript (in ES6).
I always found extremely boring implementing administrative tables, and somehow ended up creating my own library to obtain something as customizable and helpful as possible. I called it KingTable.
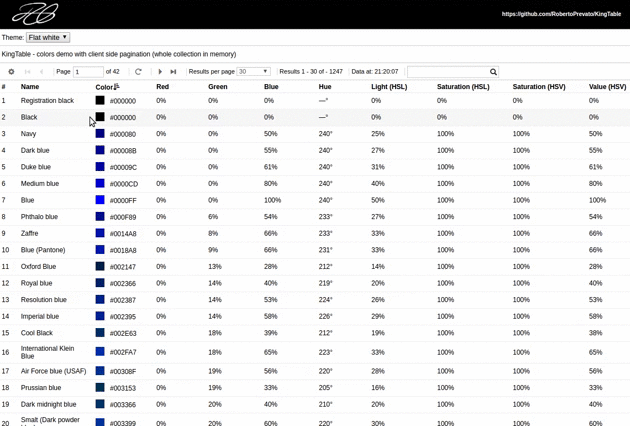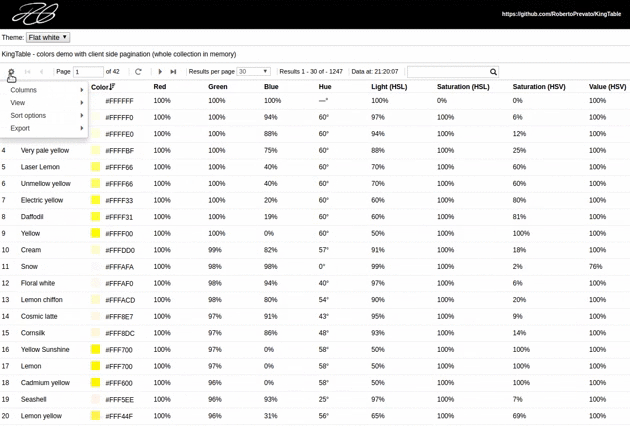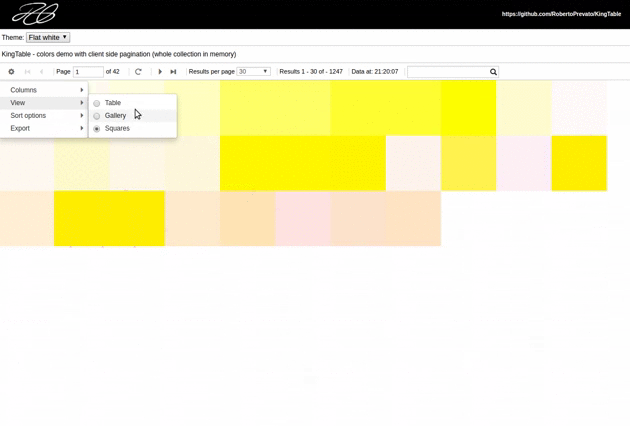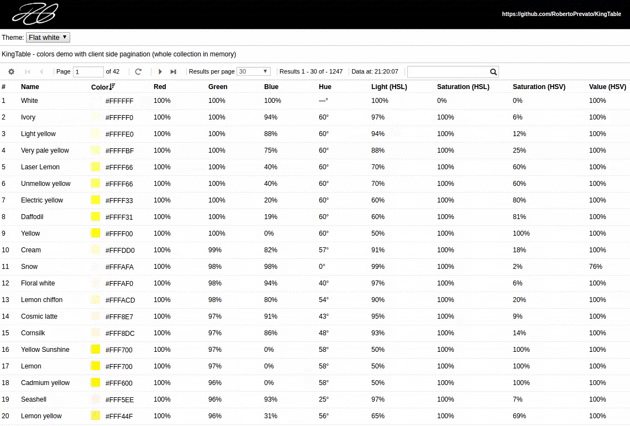
One of the main objectives of this library is to work well both for tables that require server side pagination (due to their size), and tables that can be sorted, paginated and filtered on the client side, since they display small collections that are not meant to grow over time.
The second version of the library offers many features (all listed in GitHub wiki), and I think it’s worth to describe how caching of results is facilitated, as I feel it may be useful for others.
The KingTable library implements two strategies to enable caching of table results:
- it defaults to HTTP GET method when fetching results from server side and implements code to generate alphabetically sorted query strings of filters parameters (for example
?page=4&size=30&sortBy=name×tamp=2017-05-07T00%3A50%3A06.001Z). Query strings are built automatically from filters, so programmers don’t need to do annoying string manipulations. - it implements a Least Recently Used (LRU) caching mechanism, to reduce the amount of AJAX requests even when HTTP POST is used and even when the server is not using
Cache-Controlheader
Following text describes the concepts behind this design decision. The first things will sound obvious to many, I know, but they are meant to give full picture and context.
Context
In modern web applications, data is commonly fetched when it becomes necessary to build HTML views. Following diagram illustrates a common scenario where views are built depending on URL (can be “#/hash”, browser history, query string, whatever) as users navigate between an items list view and item details view, in an administrative interface.
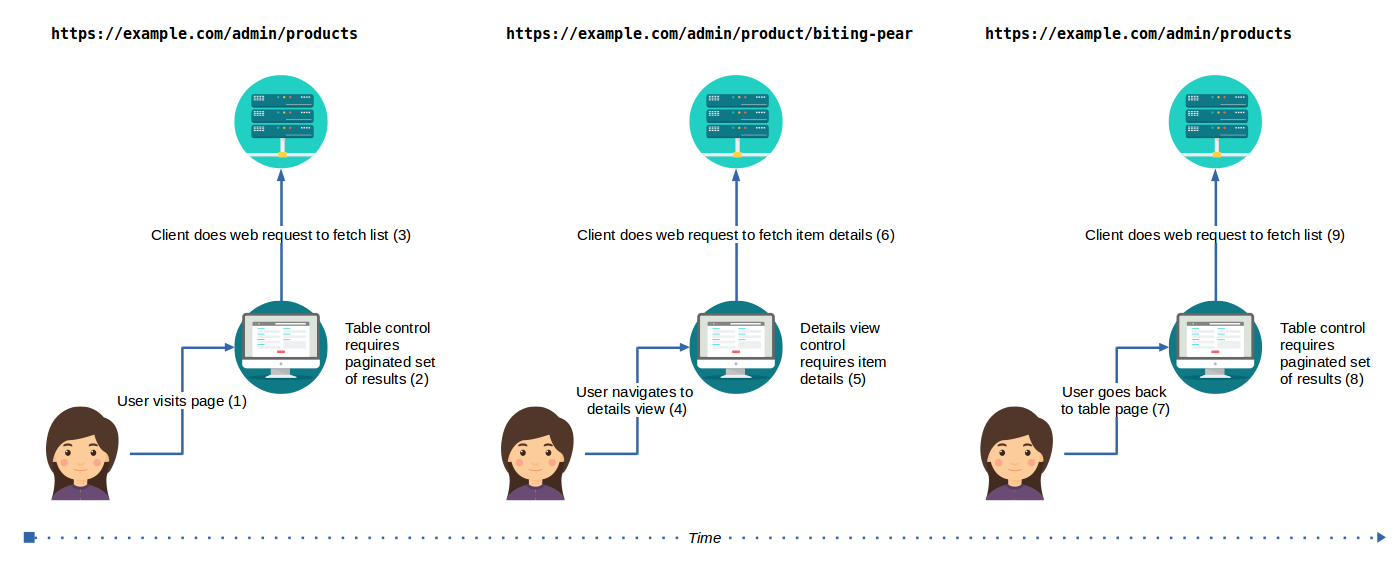
Displaying views depending on URL is a best practice, as it enables users to restore context upon page refresh, using bookmarks, sharing links, using the browser back and forth buttons. For example, displaying item details depending on click events would degrade application usability, as it wouldn’t support restoring context on page load.
A working implementation may look like this:
- User navigates to a products list page
- The client does a web request to fetch items list; when response comes, it displays the list view
- User clicks on a link to an item’s details view.
- The client does a web request to fetch item details; when response comes, displays the details view
- User navigates back to items’ list page;
- The client does a web request to fetch items list; when response comes, it displays the table of items
When users navigate frequently between pages, HTML controls may be rebuilt frequently, causing data to be fetched more often than necessary; that is, more often than it’s likely to change. If data is not supposed to change every few seconds, why a client should download data to build the interface every few seconds?
A better approach
A better approach consists of caching the response of requests, when possible, and use cached data for following requests having equivalent parameters, thus reducing the number of web requests.

Two more elements come into play:
- definition of
recent: how to tell if a resource is recent? - definition of
same: how to tell if a resource is going to be the same as before?
The standard way to do it
The standard way to deal with this issue is using HTTP GET and making the server return responses with Cache-Control header and proper configuration.
The definition of recent comes from the Cache-Control response header: the server declares how long the response data should be used.
An example of “Cache-Control” header that describes a content that should be used at most 15 minutes (900 seconds) looks like this:
"Cache-Control": "max-age: 900"
It’s like when one buys yoghurt: it has an expiration date printed on its package, the producer is giving clients a recommended deadline. It’s then up to the consumer to take action and use this information. One may ignore the expiration date and eat the yoghurt after it, or buy another yoghurt before the first expires.
The definition of same is taken from URL: if the URL is exactly the same as one used before, then it’s supposed to refer to the same resource. This is true only for resources that can be cached, because a method at the same URL may very well return ever changing responses, consider for example /api/current-time.
Browsers are implemented to handle this response header transparently, so programmers only need to use HTTP GET and use Cache-Control headers, to obtain caching quite easily: no change is required on code that creates AJAX requests.

This only works using HTTP GET¹ method and transmitting all filters criteria inside the URL. The usual way to do so is using a query string (e.g. ?hello=world).
If using HTTP GET is possible, this is the recommended way to cache results on the client side and improve user experience.
What if HTTP GET cannot be used?
Sometimes using HTTP GET is not an option.
- using GET for sensitive data is considered a bad idea, for good reasons (server logs, browsers history, possibility of leaking in URL Referrer)
- when passing filters inside URL, whether parameters should be considered sensitive information is sometimes controversial and subject to interpretation: for example, in banking systems even a transaction ID may be considered sensitive and search string may be very well considered confidential information in some circumstances (users may be searching for words that should not appear in HTTP logs on the server or in browsers history)
- HTTP GET is often victim of misconceptions: for example, many think that URL is not encrypted when using HTTPS, which is incorrect: when using HTTPS, also query string is encrypted. Generally, it’s easier to use HTTP POST and avoid time consuming discussions.
In these cases, the usual approach is to live happily with many AJAX requests, happening every single time a condition is met. However, when the objectives are:
- to do a read only operation on the server side
- to transmit filters criteria through HTTP POST, to secure them in request body
- to cache results for a limited span of time, to save resources and improve users’ experience
nothing forbids to create alternative solutions that enable reusing the response of previous requests and defining expiration policies (the meaning of ‘recent’).
LRU Caching mechanism in KingTable library
As mentioned previously, a client side caching mechanism has been implemented for the KingTable library, using storages from HTML5 Web Storage API (localStorage and sessionStorage) or compatible objects². Before generating AJAX requests with a given set of parameters, cache is examined for response data that was obtained with equivalent parameters. If no data is found, an AJAX request is generated; and its response data is cached for following requests. Cached objects include not only the response data, but also expiration time (so they can be discarded and removed if they’re old) and request input parameters. For every given request, the last n most recent responses are cached (Least Recently Used resources), to cap cache size and to make caching useful.
Caching mechanism is configurable, so users of the library can disable it, specify max age of cached items, maximum number of cached items (LRU size), and even the storage to cache items. sessionStorage is used by default, so cache is automatically removed when the browser is closed³. A custom implementation of storage can be otherwise used to cache items in page memory, only as long as page stays open and is not reloaded, which can be a good option in SPA.
I described all these options in the KingTable wiki.
- LRU cache wrapper source code.
- In-Memory Storage compatible object source code.
- Core business logic for KingTable (no DOM manipulation) source code.
And that’s all!
Easy caching that works in any circumstance and can be configured as needed!
Notes
1. Both HTTP1.1 and HTTP/2 specifications contemplate caching of HTTP POST responses containing a `Cache-Control` header. In practice, this is not how browsers are implemented. Tests using latest Chrome (I prepared a video, here), Firefox and Opera reveals how cache is not used when using HTTP POST, even if a `Cache-Control` header is sent from server to client, and even with `Content-Location`, even for following GET requests.
2. The principle of duck typing has been applied, so any object implementing the interface of storage objects works (getItem, setItem, removeItem, clear). Alex Martelli (2000): "don't check whether it IS-a duck: check whether it QUACKS-like-a duck, WALKS-like-a duck, etc, etc, depending on exactly what subset of duck-like behaviour you need to play your language-games with.".
3. Web Storage API is safe from attacks coming from other websites, as every cache is only readable from the same web domain, however the sessionStorage should be cleared automatically upon user's log out (the user could leave the browser open after logging out, potentially exposing cache data to other users using the same browser).
Links
- Interesting blog post on a bug that was introduced in an Apple update: mnot’s blog - Caching POST (24/09/2012)
- Example of caching HTTP POST responses using a forward cache proxy and creating POST request bodies digests: ebay tech blog - Caching HTTP POST Requests and Responses (08/20/2012)
- About Duck typing - don’t miss to read about Alex Martelli: Wikipedia - Duck typing ***
Icons credits:
- clock - Prosymbols - http://www.flaticon.com/authors/prosymbols
- girl - Freepik - http://www.freepik.com
- server -popcorn art - http://www.flaticon.com/authors/popcorns-arts